

Từ “Qwen-with-Questions” đến đối thủ trực tiếp của OpenAI o1
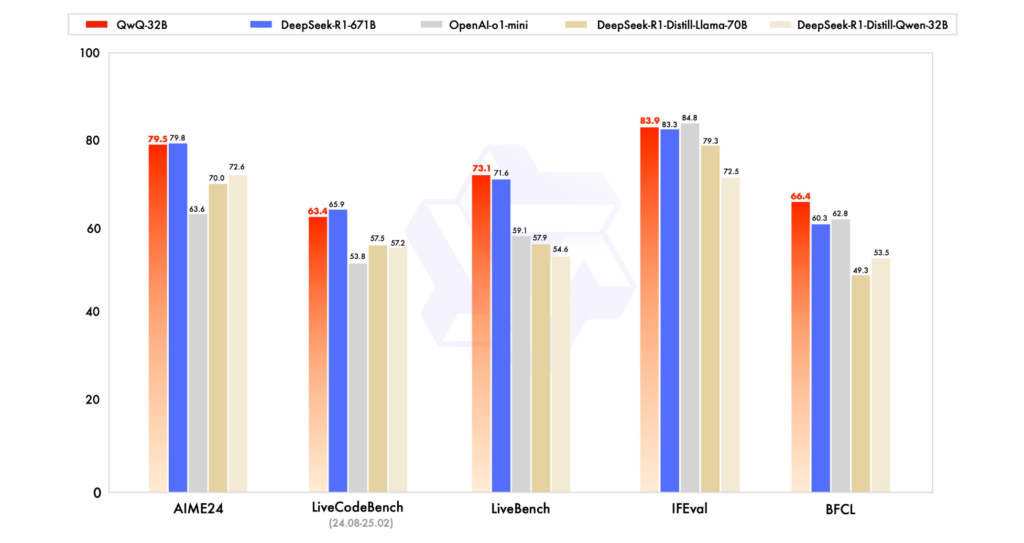
QwQ, viết tắt của “Qwen-with-Questions,” lần đầu Alibaba giới thiệu tháng 11/2024, nhằm cạnh tranh với “o1-preview” của OpenAI. Mục tiêu của QwQ là nâng cao tư duy logic và lập kế hoạch, với ưu thế đặc biệt trong toán học, lập trình. Phiên bản đầu của QwQ trang bị 32 tỉ tham số, độ dài ngữ cảnh 32000 token. Alibaba khi đó khẳng định mô hình vượt trội o1-preview ở bài toán toán học (AIME, MATH) và suy luận khoa học (GPQA). Tuy nhiên, QwQ gặp bất lợi ở bài toán lập trình như LiveCodeBench (nơi mô hình OpenAI vẫn tỏ ra ổn định hơn) và đôi lúc dính lỗi “pha trộn ngôn ngữ” hay vòng lặp logic (circular reasoning). Dù vậy, QwQ vẫn gây tiếng vang khi mở mã theo Apache 2.0, cho phép nhà phát triển và doanh nghiệp tùy ý tùy biến, thương mại hóa.
Kể từ khi QwQ xuất hiện, AI đã có nhiều đột phá. Giới nghiên cứu ngày càng nhận ra mô hình LLM truyền thống còn nhiều hạn chế, trong khi “mô hình suy luận quy mô lớn” (LRM) như “o3” (OpenAI) hay DeepSeek-R1 (Trung Quốc) sử dụng “thời gian suy luận” (inference-time reasoning) và tự phản biện để nâng độ chính xác. Tại Trung Quốc, DeepSeek-R1 đã “gây bão” từ tháng 1/2024 và bứt phá để trở thành “trang AI” được truy cập nhiều nhất, chỉ sau OpenAI. Với QwQ-32B, đội ngũ Qwen đang tận dụng những tiến bộ này bằng cách kết hợp RL và cơ chế tự-đặt-câu-hỏi (structured self-questioning), biến QwQ-32B trở thành đối thủ đáng gờm ở mảng AI suy luận.
Bứt phá hiệu năng nhờ RL nhiều giai đoạn
Các mô hình huấn luyện qua “instruction tuning” truyền thống thường chật vật với tác vụ suy luận phức tạp. Nhóm Qwen gợi ý rằng RL có thể giúp mô hình giải bài toán phức tạp tốt hơn. QwQ-32B kế thừa hướng đi này, thực hiện nhiều giai đoạn RL để nâng cao khả năng toán, lập trình và giải quyết vấn đề tổng quát.
Trong khi DeepSeek-R1 có 671 tỉ tham số (trong đó 37 tỉ “được kích hoạt”), QwQ-32B đạt hiệu năng tương đương với quy mô nhỏ hơn hẳn. Qwen khẳng định QwQ-32B thường chỉ cần 24GB VRAM trên GPU (ví dụ Nvidia H100) so với hơn 1500GB VRAM để chạy đầy đủ DeepSeek R1 trên 16 GPU A100. Điều đó thể hiện hiệu suất của Qwen nhờ cách áp dụng RL.
QwQ-32B dùng kiến trúc mô hình ngôn ngữ “causal,” với nhiều tối ưu như 64 lớp Transformer, RoPE, SwiGLU, RMSNorm, Attention QKV bias; sử dụng generalized query attention (GQA) (40 attention head cho phần query, 8 cho key-value); cho phép ngữ cảnh dài tới 131072 token. Quá trình huấn luyện đa giai đoạn gồm tiền huấn luyện, tinh chỉnh giám sát, RL:
- Giai đoạn đầu: tập trung toán và lập trình, mô hình dùng “accuracy verifier” với toán và “server thực thi mã” với lập trình, chỉ tăng cường (reinforce) câu trả lời chính xác.
- Giai đoạn hai: tập trung nâng cao năng lực toàn diện, huấn luyện qua “reward model” và bộ luật “rule-based verifier,” giúp mô hình theo sát chỉ dẫn, phù hợp với con người, đồng thời vẫn giữ vững khả năng toán, lập trình.
Ý nghĩa cho nhà quản trị doanh nghiệp
Với lãnh đạo trong doanh nghiệp (CEO, CTO, lãnh đạo CNTT, nhà phát triển AI), QwQ-32B “mở lối” cho mô hình AI hỗ trợ ra quyết định kinh doanh và đổi mới kỹ thuật. Khả năng suy luận dựa trên RL có thể cung cấp góc nhìn chi tiết hơn, có ý thức bối cảnh cao hơn, hữu ích cho công việc như phân tích dữ liệu tự động, lập kế hoạch chiến lược, phát triển phần mềm hay tự động hóa thông minh. Đặc biệt, vì có mã gốc mở, doanh nghiệp dễ tinh chỉnh hay tùy biến để phù hợp ứng dụng lĩnh vực, không chịu giới hạn “độc quyền.”
Vấn đề an ninh hoặc định kiến do nguồn gốc Trung Quốc có thể gây nghi ngờ với một số người dùng, tương tự mô hình DeepSeek-R1. Nhưng vì QwQ-32B cũng cho phép tải về qua Hugging Face (chạy ngoại tuyến, tinh chỉnh lại), nên vấn đề này có thể giải quyết. Đây là phương án khả thi nếu doanh nghiệp muốn cân nhắc DeepSeek mà e ngại hạ tầng quá “nặng.”
Phản hồi từ cộng đồng AI và nhà phát triển
Việc QwQ-32B ra mắt thu hút nhiều phản hồi tích cực:
- Ông Vaibhav Srivastav (Hugging Face) khen tốc độ suy luận nhờ hạ tầng Hyperbolic Labs, gọi nó “rất nhanh,” lại “qua mặt DeepSeek-R1, OpenAI o1-mini, giấy phép Apache 2.0.”
- Chubby (Kimmonismus), chuyên đưa tin AI, ấn tượng vì QwQ-32B đôi lúc vượt DeepSeek-R1 dù mô hình nhỏ gọn hơn 20 lần.
- Yuchen Jin (Hyperbolic Labs) tán dương: “Mô hình quy mô nhỏ vẫn mạnh, Alibaba Qwen xuất xưởng QwQ-32B, mô hình suy luận đánh bại DeepSeek-R1 (671 tỉ) lẫn OpenAI o1-mini!”
- Erik Kaunismäki (Hugging Face) đề cao sự dễ dàng triển khai, “một click” trên Hugging Face Endpoint, không đòi hỏi cài đặt phức tạp.
Khả năng “tác tử”
QwQ-32B cũng có khả năng “agentic,” tự điều chỉnh cách suy luận dựa trên phản hồi từ môi trường. Nhóm phát triển khuyến cáo các thiết lập suy luận gồm Temperature 0,6, TopP 0,95, TopK (20-40), YaRN Scaling cho ngữ cảnh dài hơn 32768 token. Mô hình chạy tốt với vLLM, một framework suy luận băng thông cao, dù vLLM hiện chỉ hỗ trợ YaRN “tĩnh” không thay đổi theo độ dài đầu vào.
Định hướng tương lai
Nhóm Qwen coi QwQ-32B mới chỉ là bước đầu trong việc “mở rộng RL” để cải thiện trí thông minh mô hình. Họ nhắm:
- Tiếp tục phát triển RL để nâng cao mức “tư duy” của mô hình.
- Hợp nhất “agents” với RL cho nhiệm vụ suy luận dài hơi.
- Nâng cấp mô hình nền (foundation model) tối ưu cho RL.
- Hướng tới trí tuệ nhân tạo tổng quát (AGI) qua kỹ thuật huấn luyện tiên tiến.
Với QwQ-32B, nhóm Qwen cho thấy RL sẽ đóng vai trò quan trọng trong thế hệ AI kế tiếp, chứng minh “không nhất thiết mô hình phải khổng lồ,” vẫn đạt hiệu năng suy luận ấn tượng.


, nhằm cải thiện hiệu suất trên các tác vụ giải quyết vấn đề phức tạp. Mô hình được cung cấp dưới dạng mã nguồn mở trên Hugging Face và ModelScope theo giấy phép Apache 2.0. Điều này nghĩa là doanh nghiệp có thể dùng ngay để phát triển sản phẩm hoặc dịch vụ thương mại.){kind=link}