

Các doanh nghiệp ngày càng dựa vào các mô hình ngôn ngữ lớn (LLM) để cung cấp các dịch vụ tiên tiến, nhưng lại gặp khó khăn trong việc xử lý chi phí tính toán của các mô hình đang chạy. Một khuôn khổ mới, chuỗi chuyên gia (CoE), nhằm mục đích giúp LLM tiết kiệm tài nguyên hơn trong khi tăng độ chính xác của chúng trong các tác vụ lý luận.
Khung CoE giải quyết những hạn chế của các phương pháp tiếp cận trước đó bằng cách kích hoạt “chuyên gia” — các thành phần tách biệt của một mô hình, mỗi thành phần chuyên về một số nhiệm vụ nhất định — theo trình tự thay vì song song. Cấu trúc này cho phép các chuyên gia truyền đạt kết quả trung gian và dần dần xây dựng dựa trên công việc của nhau.
Các kiến trúc như CoE có thể trở nên rất hữu ích trong các ứng dụng suy luận chuyên sâu, trong đó việc tăng hiệu quả có thể giúp tiết kiệm chi phí đáng kể và mang lại trải nghiệm tốt hơn cho người dùng.
LLM dày đặc và hỗn hợp các chuyên gia
Các LLM cổ điển, đôi khi được gọi là các mô hình dày đặc, kích hoạt mọi tham số đồng thời trong quá trình suy luận, dẫn đến nhu cầu tính toán mở rộng khi mô hình phát triển lớn hơn. Hỗn hợp chuyên gia (MoE), một kiến trúc được sử dụng trong các mô hình như DeepSeek-V3 và (giả định là) GPT-4o, giải quyết thách thức này bằng cách chia mô hình thành một nhóm chuyên gia.
Trong quá trình suy luận, các mô hình MoE sử dụng một bộ định tuyến chọn một tập hợp con các chuyên gia cho mỗi đầu vào. MoE làm giảm đáng kể chi phí tính toán khi chạy LLM so với các mô hình dày đặc. Ví dụ, DeepSeek-V3 là mô hình 671 tỷ tham số với 257 chuyên gia, chín trong số đó được sử dụng cho bất kỳ mã thông báo đầu vào nào, tổng cộng là 37 tỷ tham số đang hoạt động trong quá trình suy luận.
Nhưng MoE có những hạn chế. Hai nhược điểm chính là, thứ nhất, mỗi chuyên gia hoạt động độc lập với những người khác, làm giảm hiệu suất của mô hình đối với các nhiệm vụ đòi hỏi nhận thức theo ngữ cảnh và sự phối hợp giữa các chuyên gia. Và thứ hai, kiến trúc MoE gây ra tình trạng thưa thớt cao, dẫn đến mô hình có yêu cầu bộ nhớ cao, mặc dù một tập hợp con nhỏ được sử dụng tại bất kỳ thời điểm nào.
Chuỗi chuyên gia
Khung chuỗi chuyên gia giải quyết những hạn chế của MoE bằng cách kích hoạt các chuyên gia theo trình tự thay vì song song. Cấu trúc này cho phép các chuyên gia truyền đạt kết quả trung gian và dần dần xây dựng dựa trên công việc của nhau.
CoE sử dụng một quy trình lặp. Đầu vào đầu tiên được định tuyến đến một nhóm chuyên gia, những người sẽ xử lý nó và chuyển câu trả lời của họ cho một nhóm chuyên gia khác. Nhóm chuyên gia thứ hai xử lý các kết quả trung gian và có thể chuyển chúng cho nhóm chuyên gia tiếp theo. Phương pháp tuần tự này cung cấp các đầu vào có nhận thức ngữ cảnh, tăng cường đáng kể khả năng xử lý các tác vụ lý luận phức tạp của mô hình.
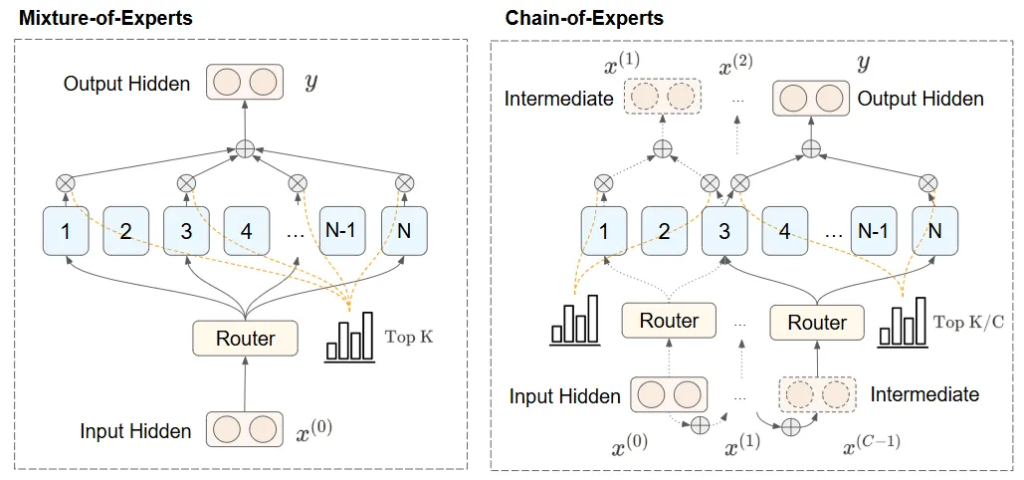
Ví dụ, trong suy luận toán học hoặc suy luận logic, CoE cho phép mỗi chuyên gia xây dựng dựa trên những hiểu biết trước đó, cải thiện độ chính xác và hiệu suất tác vụ. Phương pháp này cũng tối ưu hóa việc sử dụng tài nguyên bằng cách giảm thiểu các phép tính dư thừa thường gặp trong các triển khai chuyên gia chỉ song song, giải quyết nhu cầu của doanh nghiệp về các giải pháp AI hiệu quả về chi phí và hiệu suất cao.
Những lợi thế chính của CoE
Phương pháp tiếp cận chuỗi chuyên gia, sử dụng kích hoạt tuần tự và cộng tác chuyên gia, mang lại một số lợi ích quan trọng, như được mô tả trong một phân tích gần đây từ một nhóm các nhà nghiên cứu đang thử nghiệm khuôn khổ CoE.
Trong CoE, việc lựa chọn chuyên gia được thực hiện theo cách lặp lại. Trong mỗi lần lặp lại, các chuyên gia được xác định bởi đầu ra của giai đoạn trước. Điều này cho phép các chuyên gia khác nhau giao tiếp và hình thành sự phụ thuộc lẫn nhau để tạo ra một cơ chế định tuyến năng động hơn.
Các nhà nghiên cứu viết: “Theo cách này, CoE có thể cải thiện đáng kể hiệu suất của mô hình trong khi vẫn duy trì hiệu quả tính toán, đặc biệt là trong các tình huống phức tạp (ví dụ: nhiệm vụ Toán học trong các thí nghiệm)”.
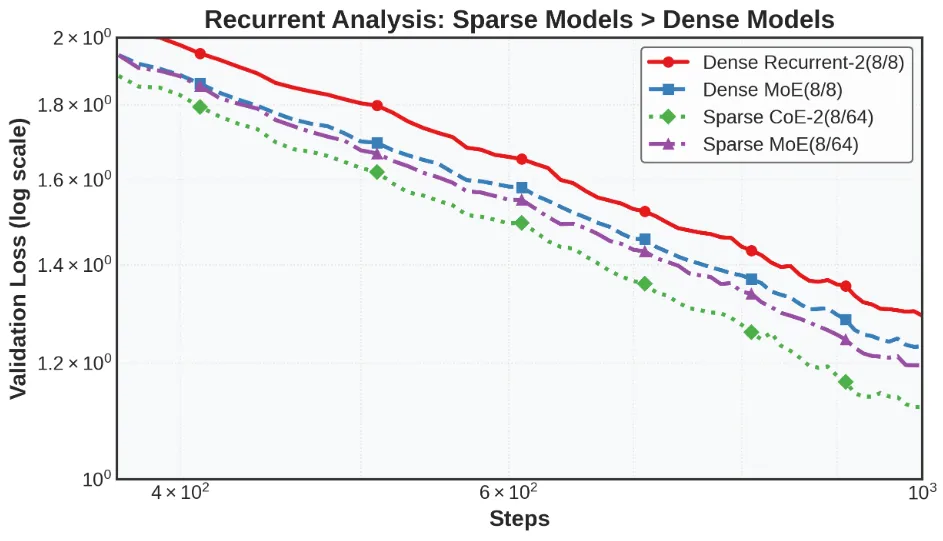
Các thí nghiệm của các nhà nghiên cứu cho thấy rằng với ngân sách tính toán và bộ nhớ bằng nhau, CoE hoạt động tốt hơn LLM và MoE dày đặc. Ví dụ, trong các chuẩn mực toán học, một CoE với 64 chuyên gia, bốn chuyên gia định tuyến và hai lần lặp suy luận (CoE-2(4/64)) hoạt động tốt hơn một MoE với 64 chuyên gia và tám chuyên gia định tuyến (MoE(8/64)).
Các nhà nghiên cứu cũng phát hiện ra rằng CoE làm giảm yêu cầu về bộ nhớ. Ví dụ, một CoE với hai trong số 48 chuyên gia được định tuyến và hai lần lặp (CoE-2(4/48)) đạt được hiệu suất tương tự như MoE(8/64) trong khi sử dụng ít chuyên gia hơn, làm giảm yêu cầu về bộ nhớ xuống 17,6%.
CoE cũng cho phép các kiến trúc mô hình hiệu quả hơn. Ví dụ, CoE-2(8/64) với bốn lớp mạng nơ-ron khớp với hiệu suất của MoE(8/64) với tám lớp, nhưng sử dụng ít hơn 42% bộ nhớ.
“Có lẽ quan trọng nhất là CoE dường như cung cấp cái mà chúng tôi gọi là sự tăng tốc ‘bữa trưa miễn phí’”, các nhà nghiên cứu viết. “Bằng cách tái cấu trúc cách thông tin chảy qua mô hình, chúng tôi đạt được kết quả tốt hơn với chi phí tính toán tương tự so với các phương pháp MoE trước đây”.
Một ví dụ điển hình: CoE-2(4/64) cung cấp thêm 823 tổ hợp chuyên gia khi so sánh với MoE(8/64), cho phép mô hình học các tác vụ phức tạp hơn mà không làm tăng kích thước của mô hình hoặc yêu cầu về bộ nhớ và tính toán của nó.
Chi phí hoạt động thấp hơn của CoE và hiệu suất được cải thiện đối với các tác vụ phức tạp có thể giúp các doanh nghiệp dễ tiếp cận AI tiên tiến hơn, giúp họ duy trì khả năng cạnh tranh mà không cần đầu tư đáng kể vào cơ sở hạ tầng.
Các nhà nghiên cứu viết: “Nghiên cứu này mở ra những con đường mới để mở rộng quy mô các mô hình ngôn ngữ một cách hiệu quả, có khả năng giúp các năng lực trí tuệ nhân tạo tiên tiến dễ tiếp cận và bền vững hơn”.

 mới, tuyên bố hiệu suất hàng đầu trên toàn cầu")
{kind=link}