

Hiểu về Llama 4 Maverick và Llama 4 Scout
Trước khi tìm hiểu về việc sử dụng API, hãy nắm vững các thông số cốt lõi của các mô hình này. Llama 4 giới thiệu tính đa phương thức bản địa, có nghĩa là nó xử lý văn bản và hình ảnh cùng nhau từ đầu. Thêm vào đó, thiết kế MoE của nó chỉ kích hoạt một phần tập tham số cho mỗi nhiệm vụ, tăng cường hiệu suất.
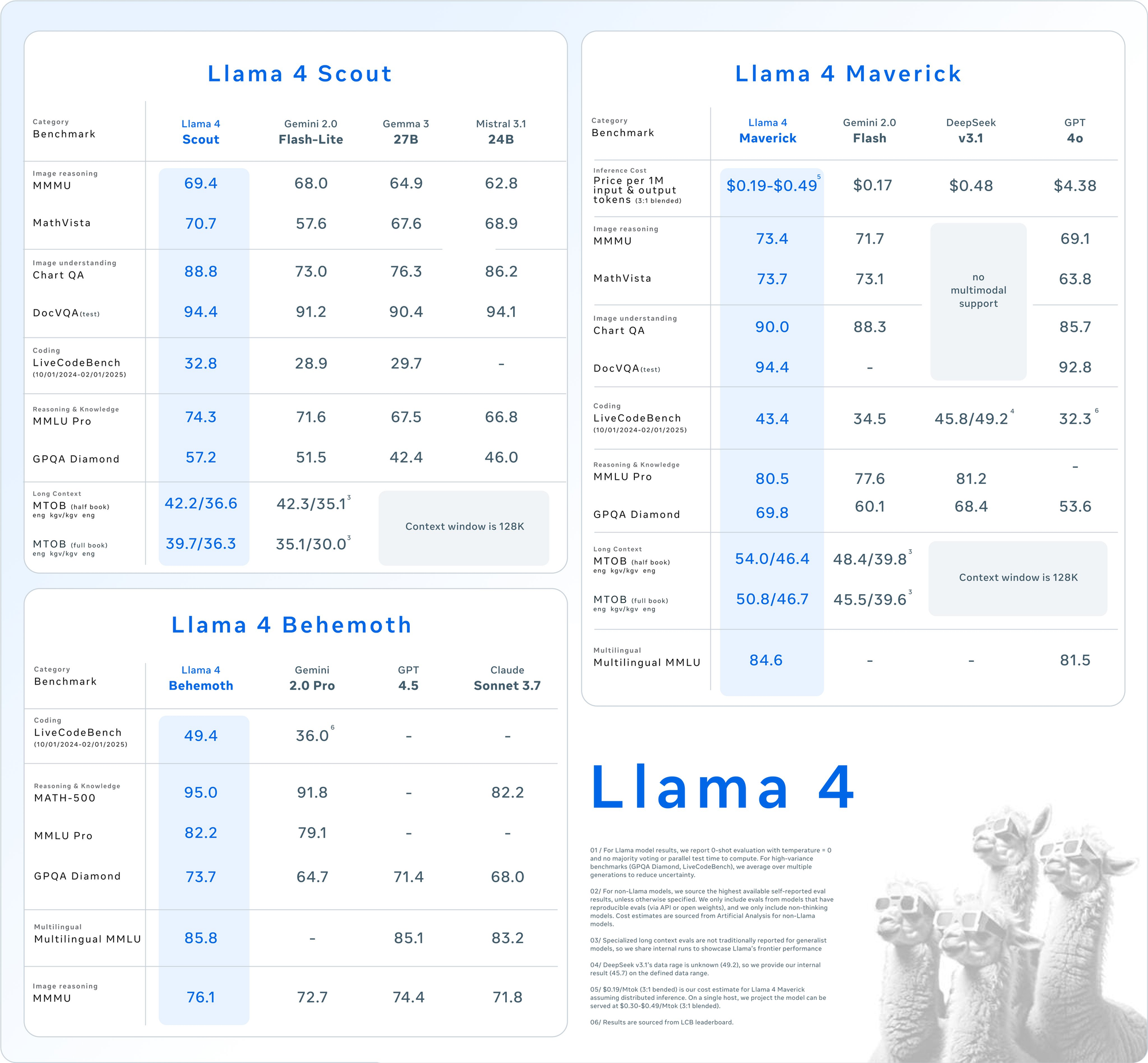
Llama 4 Scout: Công Cụ Đa Phương Thức Hiệu Quả
- Các tham số: 17 tỷ được kích hoạt, 109 tỷ tổng cộng, 16 chuyên gia.
- Cửa sổ ngữ cảnh: Lên đến 10 triệu token.
- Các tính năng chính: Xuất sắc trong các nhiệm vụ ngữ cảnh dài như tóm tắt nhiều tài liệu và lý luận trên các mã nguồn lớn. Nó phù hợp trên một GPU NVIDIA H100 với định dạng INT4.
- Trường hợp sử dụng: Phù hợp cho các nhà phát triển cần xử lý đa phương thức nhanh chóng và tiết kiệm tài nguyên.
Llama 4 Maverick: Cỗ Máy Đa Dụng
- Các tham số: 17 tỷ được kích hoạt, 400 tỷ tổng cộng, 128 chuyên gia.
- Cửa sổ ngữ cảnh: Lên đến 1 triệu token.
- Các tính năng chính: Cung cấp hiểu biết chất lượng cao về văn bản và hình ảnh, hỗ trợ 12 ngôn ngữ (ví dụ: Tiếng Anh, Tây Ban Nha, Hindi). Nó được tối ưu hóa cho hội thoại và viết sáng tạo.
- Trường hợp sử dụng: Thích hợp cho các trợ lý doanh nghiệp và ứng dụng đa ngôn ngữ.
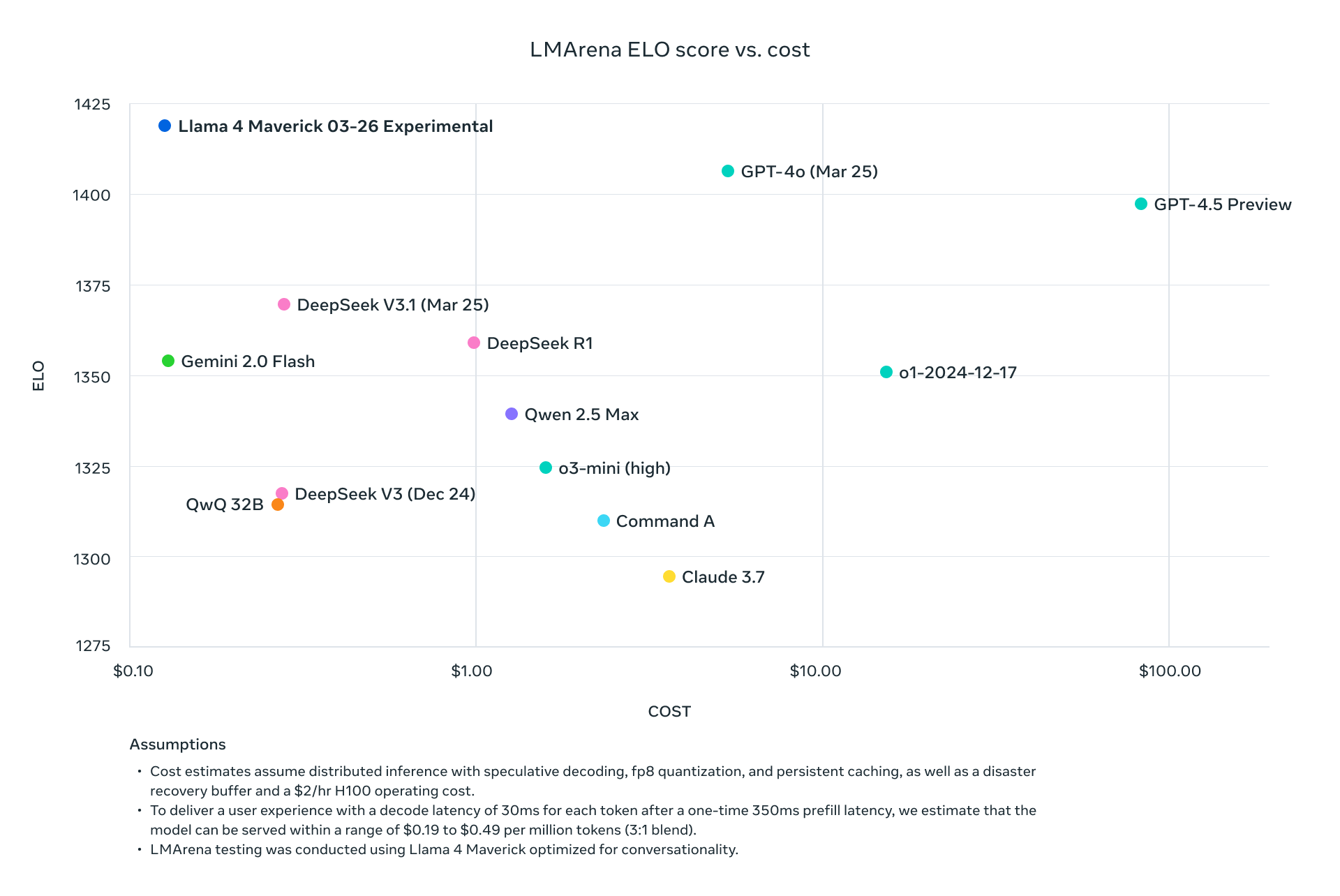
Cả hai mô hình đều vượt trội hơn các thế hệ trước như Llama 3 và cạnh tranh với các ông lớn trong ngành như GPT-4o, khiến chúng trở thành những lựa chọn hấp dẫn cho các dự án chạy API.
Tại Sao Sử Dụng API Llama 4?
Tích hợp Llama 4 qua API loại bỏ nhu cầu lưu trữ các mô hình khổng lồ này tại chỗ, thường yêu cầu phần cứng đáng kể (ví dụ: NVIDIA H100 DGX cho Maverick). Thay vào đó, các nền tảng như Groq, Together AI và OpenRouter cung cấp các API được quản lý, mang đến:
- Khả năng mở rộng: Xử lý khối lượng khác nhau mà không cần hạ tầng bổ sung.
- Hiệu quả chi phí: Trả tiền theo từng token, với mức giá thấp tới $0.11/M token đầu vào (Scout trên Groq).
- Dễ sử dụng: Truy cập các tính năng đa phương thức với các yêu cầu HTTP đơn giản.
Kế tiếp, hãy thiết lập môi trường của bạn để gọi các API này.
Thiết Lập Môi Trường Của Bạn Để Gọi API Llama 4
Để tương tác với Llama 4 Maverick và Llama 4 Scout qua API, hãy chuẩn bị môi trường phát triển của bạn. Làm theo các bước sau:
Bước 1: Chọn Nhà Cung Cấp API
Nhiều nền tảng cung cấp các API Llama 4. Dưới đây là một số tùy chọn phổ biến:
- Groq: Cung cấp dịch vụ suy diễn với chi phí thấp (Scout: $0.11/M đầu vào, Maverick: $0.50/M đầu vào).
- Together AI: Cung cấp các endpoint tùy chỉnh với khả năng mở rộng riêng.
- OpenRouter: Có cấp độ miễn phí, lý tưởng cho việc kiểm tra.
- Cloudflare Workers AI: Triển khai không máy chủ với hỗ trợ Scout.
Đối với hướng dẫn này, chúng tôi sẽ sử dụng Groq và Together AI làm ví dụ do tài liệu và hiệu suất của chúng.
Bước 2: Lấy API Keys
- Groq: Đăng ký tại groq.com, điều hướng đến Bảng Điều Khiển Nhà Phát Triển và tạo API key.
- Together AI: Đăng ký tại together.ai, sau đó truy cập API key của bạn từ bảng điều khiển.
Lưu trữ những key này một cách an toàn (ví dụ: trong các biến môi trường) để tránh việc mã hóa cứng chúng.
Bước 3: Cài Đặt Các Thư Viện
Sử dụng Python để đơn giản hóa. Cài đặt các thư viện cần thiết:
pip install requests
Để kiểm tra, Apidog bổ sung cấu hình này cho bạn bằng cách cho phép bạn gỡ lỗi các endpoint API một cách trực quan.
Thực Hiện Cuộc Gọi API Llama 4 Đầu Tiên Của Bạn
Khi môi trường của bạn đã sẵn sàng, gửi một yêu cầu đến API Llama 4. Hãy bắt đầu với một ví dụ đơn giản về việc tạo văn bản.
Ví dụ 1: Tạo Văn Bản với Llama 4 Scout (Groq)
import requests
import os
# Đặt API key
API_KEY = os.getenv("GROQ_API_KEY")
URL = "https://api.groq.com/v1/chat/completions"
# Định nghĩa payload
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": "Viết một bài thơ ngắn về AI."}
],
"max_tokens": 150,
"temperature": 0.7
}
# Đặt headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Gửi yêu cầu
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Đầu ra: Một bài thơ ngắn gọn được tạo bởi Scout, tận dụng kiến trúc MoE hiệu quả của nó.
Ví dụ 2: Đầu vào đa phương thức với Llama 4 Maverick (Together AI)
Maverick tỏa sáng trong các nhiệm vụ đa phương thức. Đây là cách để mô tả một hình ảnh:
import requests
import os
# Đặt API key
API_KEY = os.getenv("TOGETHER_API_KEY")
URL = "https://api.together.ai/v1/chat/completions"
# Định nghĩa payload với hình ảnh và văn bản
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/sample.jpg"}
},
{
"type": "text",
"text": "Mô tả hình ảnh này."
}
]
}
],
"max_tokens": 200
}
# Đặt headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Gửi yêu cầu
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Đầu ra: Một mô tả chi tiết về hình ảnh, thể hiện sự kết hợp giữa hình ảnh và văn bản của Maverick.
Tối Ưu Hóa Các Yêu Cầu API Để Cải Thiện Hiệu Suất
Để tối đa hóa hiệu quả, điều chỉnh các cuộc gọi API của Llama 4. Hãy xem xét những kỹ thuật này:
Điều Chỉnh Độ Dài Ngữ Cảnh
- Scout: Sử dụng cửa sổ 10 triệu token của nó cho các tài liệu dài. Đặt
max_model_len(nếu được hỗ trợ) để xử lý các đầu vào lớn. - Maverick: Giới hạn trong 1 triệu token cho các ứng dụng trò chuyện để cân bằng giữa tốc độ và chất lượng.
Tinh Chỉnh Các Tham Số
- Nhiệt độ: Thấp hơn (ví dụ: 0.5) cho các phản hồi dựa trên sự thật, cao hơn (ví dụ: 1.0) cho sự sáng tạo.
- Số Token Tối Đa: Giới hạn độ dài đầu ra để tránh tính toán không cần thiết.
Xử Lý Theo Lô
Gửi nhiều hướng dẫn trong một yêu cầu (nếu API hỗ trợ) để giảm độ trễ. Kiểm tra tài liệu nhà cung cấp để biết các endpoint theo lô.
Các Trường Hợp Sử Dụng Nâng Cao Với API Llama 4
Bây giờ, hãy khám phá các tích hợp nâng cao để mở khóa toàn bộ tiềm năng của Llama 4.
Trường Hợp Sử Dụng 1: Chatbot Đa Ngôn Ngữ
Maverick hỗ trợ 12 ngôn ngữ. Xây dựng một bot hỗ trợ khách hàng:
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{"role": "user", "content": "Hola, ¿cómo puedo resetear mi contraseña?"}
],
"max_tokens": 100
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Đầu ra: Một phản hồi bằng tiếng Tây Ban Nha, tận dụng sự thông thạo đa ngôn ngữ của Maverick.
Trường Hợp Sử Dụng 2: Tóm Tắt Tài Liệu Với Scout
Cửa sổ 10 triệu token của Scout xuất sắc trong việc tóm tắt các văn bản lớn:
long_text = "..." # Chèn một tài liệu dài ở đây
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": f"Tóm tắt điều này: {long_text}"}
],
"max_tokens": 300
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Đầu ra: Một bản tóm tắt ngắn gọn, được xử lý hiệu quả bởi Scout.
Gỡ Rối Và Kiểm Tra Với Apidog
Kiểm tra các API có thể khá khó khăn, đặc biệt với các đầu vào đa phương thức. Đây là nơi Apidog tỏa sáng:
- Giao Diện Trực Quan: Xây dựng và gửi các yêu cầu mà không cần mã hóa.
- Theo Dõi Lỗi: Xác định các vấn đề như hạn mức tỷ lệ hoặc nội dung không chính xác.
- Các Phản Hồi Giả Mạo: Giả lập các đầu ra của Llama 4 cho phát triển giao diện người dùng.
Để kiểm tra các ví dụ trên trong Apidog:
- Mở Apidog và tạo một yêu cầu mới.
- Đặt URL (ví dụ:
https://api.groq.com/v1/chat/completions).

- Thêm các header (
Authorization,Content-Type).
- Đính kèm payload JSON.

- Gửi và xem lại phản hồi.

Quy trình công việc này đảm bảo việc tích hợp API Llama 4 của bạn diễn ra suôn sẻ.
So Sánh Các Nhà Cung Cấp API Cho Llama 4
Chọn nhà cung cấp phù hợp ảnh hưởng đến chi phí và hiệu suất. Dưới đây là một bảng tóm tắt:
| Nhà cung cấp | Hỗ trợ Mô Hình | Bảng giá (Đầu vào/Đầu ra mỗi M) | Giới hạn Ngữ cảnh | Ghi chú |
|---|---|---|---|---|
| Groq | Scout, Maverick | $0.11/$0.34 (Scout), $0.50/$0.77 (Maverick) | 128K (có thể mở rộng) | Chi phí thấp nhất, tốc độ cao |
| Together AI | Scout, Maverick | Tùy chỉnh (các endpoint chuyên dụng) | 1M (Maverick) | Có thể mở rộng, tập trung vào doanh nghiệp |
| OpenRouter | Cả hai | Có cấp độ miễn phí | 128K | Tốt cho việc kiểm tra |
| Cloudflare | Scout | Dựa trên mức sử dụng | 131K | Đơn giản không cần máy chủ |
Chọn dựa trên quy mô và ngân sách của dự án của bạn. Đối với việc prototyping, hãy bắt đầu với cấp độ miễn phí của OpenRouter, sau đó mở rộng với Groq hoặc Together AI.
Những Thực Hành Tốt Nhất Để Tích Hợp API Llama 4
Để đảm bảo tích hợp mạnh mẽ, hãy làm theo các hướng dẫn sau:
- Giới Hạn Tỷ Lệ: Tôn trọng giới hạn của nhà cung cấp (ví dụ: 100 yêu cầu/phút trên Groq). Thực hiện việc ngủ xếp tầng cho các lần thử lại.
- Xử Lý Lỗi: Bắt các lỗi HTTP (ví dụ: 429 Quá Nhiều Yêu Cầu) và ghi lại chúng.
- Bảo Mật: Mã hóa API key và sử dụng endpoint HTTPS.
- Theo Dõi: Theo dõi việc sử dụng token để quản lý chi phí, đặc biệt với tỷ lệ cao hơn của Maverick.
Khắc Phục Các Vấn Đề Thường Gặp Với API
Gặp vấn đề? Giải quyết nhanh chóng:
- 401 Chưa Xác Thực: Kiểm tra API key của bạn.
- 429 Tỷ Lệ Giới Hạn Đã Vượt Qua: Giảm tần suất yêu cầu hoặc nâng cấp gói của bạn.
- Lỗi Payload: Đảm bảo định dạng JSON tương thích với thông số kỹ thuật của nhà cung cấp (ví dụ: mảng
messages).
Apidog giúp chẩn đoán những vấn đề này một cách trực quan, tiết kiệm thời gian.
Kết Luận
Tích hợp Llama 4 Maverick và Llama 4 Scout qua API giúp các nhà phát triển xây dựng các ứng dụng tiên tiến với chi phí tối thiểu. Dù bạn cần hiệu quả ngữ cảnh dài của Scout hay sức mạnh đa ngôn ngữ của Maverick, các mô hình này cung cấp hiệu suất hàng đầu thông qua các endpoint dễ truy cập. Bằng cách làm theo hướng dẫn này, bạn có thể thiết lập, tối ưu hóa và khắc phục sự cố các cuộc gọi API của mình một cách hiệu quả.


, cho phép xử lý hiệu quả văn bản và hình ảnh với tỷ lệ hiệu suất trên chi phí đáng chú ý. Các nhà phát triển có thể tận dụng những khả năng này thông qua các API do nhiều nền tảng cung cấp, giúp tích hợp vào ứng dụng một cách liền mạch và mạnh mẽ.){kind=link}